人類蛋白質編碼基因組的特徵化是科學研究的主要目標之一,因為它是研究人類健康的基礎。然而,過去分析中遺漏了哪些內容仍是根本問題。過去十年中,非典型開放閱讀框(ncORFs)的翻譯已在多種人類細胞類型和疾病狀態中被觀察到,這對生物醫學科學具有重大意義。然而,關鍵的知識缺口在於哪些ncORFs產生了微蛋白質或替代蛋白分子,並對人類蛋白質組有貢獻。我們報告了TransCODE聯盟的合作成果,建立了ncORFs蛋白質層面的共識圖譜。分析95,520個蛋白質組實驗後,我們發現約25%的7,264個ncORFs產生可檢測的肽段。我們開發了ncORF編碼微蛋白質的人類蛋白註解框架,並提出“肽蛋白”(peptideins)的新概念,指具有不確定功能潛力的微蛋白質。為探討肽蛋白的生物學意義,我們創建了名為ORF相對分支長度(ORBL)的進化分析方法,發現進化約束普遍存在,且與ncORF衍生肽段的觀察相關。我們還鑑定出一種來自長非編碼RNA OLMALINC的肽蛋白具有泛必需的細胞表型。整體而言,我們提供了由GENCODE和PeptideAtlas支持的公共研究工具,推動了對人類蛋白質組中未充分研究組分的生物醫學發現。
近年來,人類基因組是否編碼超過約19,500個典型蛋白質編碼基因的問題引發熱烈討論。蛋白質編碼基因是生物醫學研究的基石,包括絕大多數藥物開發計劃。因此,任何蛋白質編碼基因的新增都會對生命科學產生深遠影響。
這些基因的整理和維護由參考註解項目負責,如Ensembl-GENCODE和UniProtKB/Swiss-Prot,這些工作基於人類基因組計劃。雖然典型蛋白質編碼基因數量持續被精確化,但直到最近發現數千個未註解的ncORFs翻譯出小肽或蛋白質序列,這些被稱為微蛋白質、小ORF編碼肽(SEPs)或微肽。這些ncORFs及其編碼的肽段被廣泛認為是“暗蛋白質組”的一部分,並在疾病遺傳基礎、癌症機制及癌症特異性免疫治療靶點中展現出重要價值。
然而,哪些ncORFs是真正的蛋白質編碼基因仍具爭議。迄今為止,少數微蛋白質被參考註解目錄(如GENCODE和UniProt)標註為典型蛋白,因其結構不確定和進化約束低,難以歸類為傳統蛋白。同時,來自隱秘翻譯的肽段成為癌症等疾病治療靶點的新興領域。
2022年,我們啟動了國際TransCODE聯盟,旨在制定ncORFs及其編碼微蛋白的參考註解標準,成員包括GENCODE、PeptideAtlas、HUPO-HPP及HUPO-HIPP等。本文提出了當有高質量蛋白質組學支持時,將微蛋白質註解為人類蛋白的流程。為了正式註解較少研究的微蛋白質,我們引入“肽蛋白”分類,與傳統蛋白並列。通過功能基因組學和進化約束分析,我們篩選出具有蛋白質編碼基因特徵的肽蛋白示例。最後,我們提出基於多聯盟共識的研究議程,指導未來將ncORFs、微蛋白質和肽蛋白從研究發現推向生物學、社會及生物醫學影響的標準化註解工作。
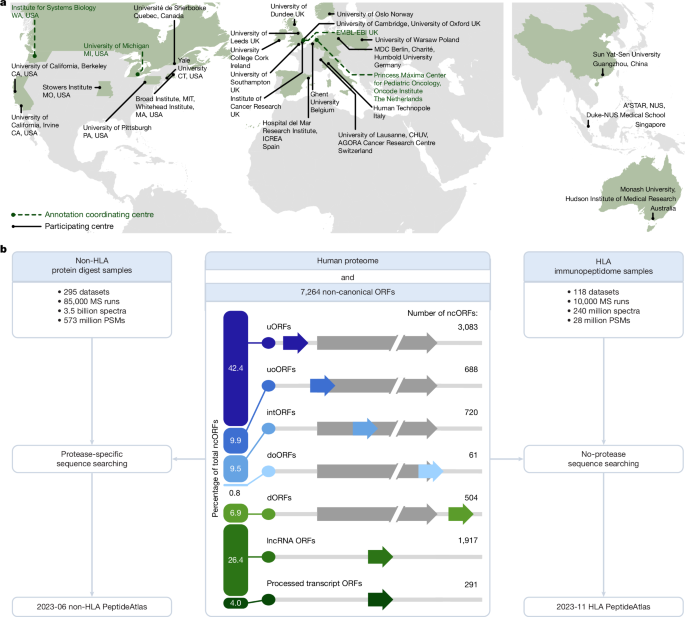
我們擴展了PeptideAtlas平台,該平台是HUPO和HPP認證人類蛋白質編碼基因的基礎。利用ProteomeXchange質譜數據庫,我們組建了非HLA和HLA肽段的PeptideAtlas版本,涵蓋數十億質譜數據,並用以查詢7,264個GENCODE支持的ncORFs。為確保高質量檢測,我們設定蛋白質層面假陽性率低於0.1%,並遵循HUPO-HPP指南,要求兩條獨特且長度不少於9個氨基酸的肽段,蛋白質覆蓋至少18個氨基酸。此方法比多數研究更嚴格,確保註解級蛋白質組學證據的可靠性。
分析結果顯示,約2.5%的ncORFs產生可檢測肽段,並通過手動審查質譜和核糖體測序數據排除假陽性。利用合成肽段和標記肽段的平行反應監測,我們確認了內源性微蛋白質的表達,並發現多種翻譯後修飾。
考慮到微蛋白質小尺寸可能影響胰蛋白酶消化肽段的檢測,我們發現使用其他蛋白酶可增加微蛋白質的識別數量和覆蓋度。HLA肽段分析顯示,約24.6%的ncORFs在HLA-I類肽段中被檢測到,表明這些微蛋白質主要來自細胞內蛋白翻譯產物。
微蛋白質的檢測受序列長度、ncORF在RNA中的位置等因素影響,但癌症與非癌症樣本間無顯著差異。手動審查HLA-I質譜和核糖體測序數據後,88.7%的ncORFs獲得驗證,且多次研究報告的ncORFs驗證率更高。
HLA-I肽段結合預測與免疫肽組學數據高度一致,支持微蛋白質肽段的真實性。微蛋白質肽段與典型蛋白肽段在HLA結合預測上無顯著差異,且在不同樣本類型中均有良好匹配。
我們發現微蛋白質的氨基酸序列、長度及組織表達模式均影響其在HLA-I數據中的可檢測性。檢測到的微蛋白質等電點較高,且其C端肽段在HLA呈現中富集,顯示C端肽段更易被加工和呈現。RNA表達量較高的微蛋白質更易被檢測,且不同組織中微蛋白質肽段比例存在細微差異,暗示組織特異性調控。
傳統上,ncORFs及其微蛋白質缺乏明顯的進化約束,限制了其蛋白質編碼基因的解釋。我們開發了ORF相對分支長度(ORBL)方法,通過多物種基因組比對,量化ORF的起始密碼子、終止密碼子及閱讀框的保守性,獲得ORBLv分數,並通過與未翻譯ORF的比較計算約束分數ORBLq。
分析顯示,約30%的ncORFs具有顯著的ORF層面進化約束,尤其是上游ORFs(uORFs)和重疊ORFs,表明存在大量保守的功能性調控元件。相比之下,只有少數ncORFs在氨基酸序列層面顯示保守。ORBLq分數與HLA-I肽段檢測呈正相關,支持進化約束與蛋白質合成的聯繫。
我們提出了一套基於蛋白質組學、免疫肽組學和核糖體測序數據的ncORF分級系統,旨在簡化其註解和生物學解釋。經過手動審查,我們確定了15個具備典型蛋白質編碼基因資格的ncORFs,部分已被GENCODE正式註解為蛋白質編碼基因。
對於尚無足夠證據支持傳統蛋白質編碼基因地位的ncORFs,我們引入“肽蛋白”概念,指具有實驗證實的翻譯和蛋白質合成,但功能尚不明確的翻譯產物。肽蛋白的判定依據包括肽段數量、是否僅在癌症樣本中檢測到、進化約束及功能研究結果。
我們利用CRISPR-Cas9基因敲除篩選,結合RNA表達和翻譯數據、HLA肽段證據、25個CRISPR篩選的元分析及ORBL進化約束評估,鑑定出51個具有泛必需性表型的ncORFs,其中6個具備肽蛋白或蛋白質編碼基因候選資格。
以c2riboseqorf47為例,該uORF具有敲除致死表型、高ORBLq分數、正向PhyloCSF分數及非人哺乳動物翻譯證據,並被GENCODE註解為蛋白質編碼基因。其他肽蛋白如c10riboseqorf92則在癌細胞中表現出重要功能,但尚缺乏正常生理功能證據。
我們提出未來研究應聚焦於:HUPO-HPP蛋白質驗證指南對微蛋白質的適用性、HLA免疫肽組學在蛋白質編碼基因註解中的角色、癌症樣本肽段對註解的影響、進化推斷在註解中的作用、支持蛋白質編碼基因註解的實驗方法、無法明確功能的微蛋白質如何註解,以及深度學習技術在註解中的應用。
本研究整合多聯盟力量,推動對ncORFs及其編碼微蛋白質的標準化理解,並提出肽蛋白概念以解決蛋白質識別與蛋白質編碼基因註解間的矛盾。我們開發的ORBL方法、CRISPR功能分析及HLA免疫肽支持,促成了新蛋白質編碼基因的發現。
此外,我們強調新技術如多蛋白酶消化、合成肽標準及翻譯後修飾分析,有助於微蛋白質的質譜識別。許多ncORFs產生免疫肽但缺乏胰蛋白酶肽段,可能因蛋白質穩定性低下。結構分析工具如AlphaFold是否能預測穩定蛋白仍待研究。
肽蛋白的註解有助於其進一步研究及醫學應用,特別是在癌症免疫治療中。人類遺傳學社群也越來越關注ncORFs及其翻譯產物在遺傳疾病中的作用。
最後,我們指出目前工作的四大限制,包括樣本類型對註解的影響、數據依賴性質譜方法的限制等,並強調未來需結合更多技術與數據提升ncORFs及微蛋白質的註解準確性與生物學理解。